Size and complexity of DATEX II class model is one of problems users have to tackle, when adopting DATEX II. In this article I do not try to solve this, but rather try to look closer, how large the model really is and how it evolves in time.
When preparing data about latest DATEX II version (v2.3) for our DATEX II Browser, I could compare some metrics with version 2.2 and decided to look a bit further back to the past. Here is what I have collected:
| Version | Released | Packages | Classes | Attributes | Enums | Enum Literals | Data Types | All |
|---|---|---|---|---|---|---|---|---|
| v1.0 | 2009-07 | 46 | 242 | 362 | 117 | 1230 | 34 | 2031 |
| v2.0 | 2011-06 | 83 | 238 | 471 | 128 | 1530 | 36 | 2486 |
| v2.1 | 2012-05 | 90 | 262 | 578 | 139 | 1622 | 38 | 2729 |
| v2.2 | 2013-05 | 90 | 262 | 578 | 139 | 1622 | 38 | 2729 |
| v2.3 | 2014-09 | 107 | 334 | 753 | 189 | 3131 | 42 | 4556 |
Note: I abbreviated "Enumeration" into "Enum".
Numbers are best seen in charts:
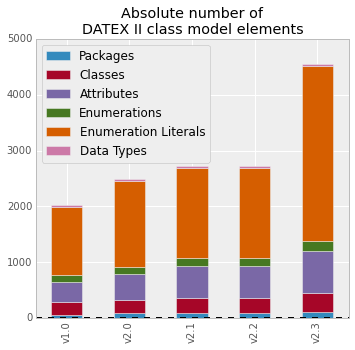
Here we see following evolution:
From v1.0 to v2.0 - rebuild
With DATEX II, major versions shall be backward compatible (as much as it is technically possible), so the only chance to do major rewrite of the model is when incrementing major version. Anyway, such modification mostly do not affect size of the model significantly, in some cases it even removes some items to keep it simpler.
Version v2.0 introduces VMS Publication and it had major share in the growth of the model.
From v2.0 to v2.1 - Introducing Parking
As usually, each version is fixing some bugs and smaller issues.
Anyway, v2.1 is for the first time providing publications for Parking and it results in model being a bit bigger again.
From v2.1 to v2.2 - Pure bug fixing
This version only fixes three issues and the size stays exatly the same.
From v2.2 to v2.3 - OpenLR, SRTI and full blown Parking
Here we see the biggest size change ever.
This time the model deals with three topics:
- OpenLR extension
- SRTI - Safety Related Traffic Information
- Parking is completed now (includes urban as well as truck parking)
The biggest contribution to size comes from Parking, partially because it is really complex topic, and partially because it in fact covers two specific areas at once - urban parking and truck parking.
Which part of class model contributes most?
Another view can be to see all types of items used in the model and compare relative growth in number of items in time.
As v2.0 is sort of current baseline, I have decided to compare all sizes to this version.
First, let us see the numbers in a table:
|Version|Packages|Classes|Attributes|Enums|Enum Literals|Data Types|All| |-------|-------:|------:|---------:|-----------:|-------------------:|-------------:| |v1.0| 55| 102| 77| 91| 80| 94| 82| |v2.0| 100| 100| 100| 100| 100| 100| 100| |v2.1| 108| 110| 123| 109| 106| 106| 110| |v2.2| 108| 110| 123| 109| 106| 106| 110| |v2.3| 129| 140| 160| 148| 205| 117| 183|
In v2.0 are all values 100 (%), others are showing values relative to this baseline.
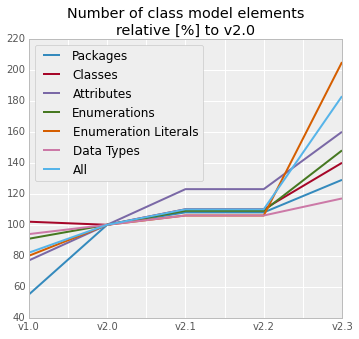
This allows to investigate, how are different types of class model items evolving in time:
Packages - grow with number of topics
With each "big topic", typically represented by new set of publications, the number of packages slowly grows, but is small in number.
Classes - the more complex topic, the bigger growth
The more complex topic is solved, the more classes are needed to describe them. Classes always grow faster than number of packages.
Attributes - grow with level of details
The bigger level of detail is required, the higher number of attributes is needed. Attributes are always growing faster than classes.
Enumerations - fast growth with complexity
As soon as new big topics require many different enumerations, the complexity grows really fast as many enumeration literals will be introduced.
Enumeration literals - biggest contributor to model size in last upgrade
Enumeration literals are naturally more numerous than number of enumerations, that is why, they could almost "explode" size of the overall model.
Data types - stable and small in number
There is only a few data types in the model and they do not grow with new topics.
Conclusions
Complexity of DATEX II model must be ballanced with the domain it serves.
- If it is smaller than needed, it would not serve the purpose.
- If it is bigger then needed, it adds complexity, which is not necessary
As DATEX II is adopting new topics into the domain, we have to accept the growth of the model.
Anyway, we must be very carefull with enhancing the model and special care must be taken with introducing new enumerations, as they could contribute to overall size of the class model most (indireclty via embeded enumeration literals).
With adding any new features, we shall ballance two approaches: - Trying to please everybody (and accepting many new features) versus Being brave to reject or remove, what is not really needed.
The best tool for this model finetuning is my favourite Occam's Razor.
In case, you would have difficulties to persuade someone to give up some requirements, which you feel are not really necessary, I can offer you two things:
- Send the person link to this blog entry to understand the problem of growing DATEX II class model complexity.
- Let me know about the case and I will try to add short blog entry about it into (to be created) Gallery of wiselly rejected requirements
It is all about keeping our DATEX II usable in long term.